大模型基础知识
大模型基础知识
原文链接:https://www.yuque.com/yopai/pp6bv5/yb0kwpfd31czdr7o
人工智能关系
人工智能 (AI)
│
┌───────────────┼───────────────┐
│ │ │
机器学习 符号AI 机器人学
│
深度学习
│
Transformer架构
│
大模型 ←────── 当前AI产品的主要技术基础
│
└──→ 对话助手 │ 编程工具 │ 多模态生成 │ 企业平台
(各类AI产品)机器学习

人工智能、机器学习、深度学习和生成式 AI 之间有何关系。
在 AI 的体系下,核心便是机器学习,即通过训练算法构建模型,让模型基于数据完成预测或决策。机器学习涵盖大量技术,可让计算机从数据中学习并进行推理,无需针对特定任务做显性编程。
机器学习中最主流的算法之一,便是神经网络(亦称人工神经网络)。神经网络参照人类大脑的结构与功能构建。神经网络由相互连接的节点层(类似于神经元)构成,可协同处理并分析复杂数据。神经网络尤其适合在海量数据中识别复杂模式与关联关系的任务。
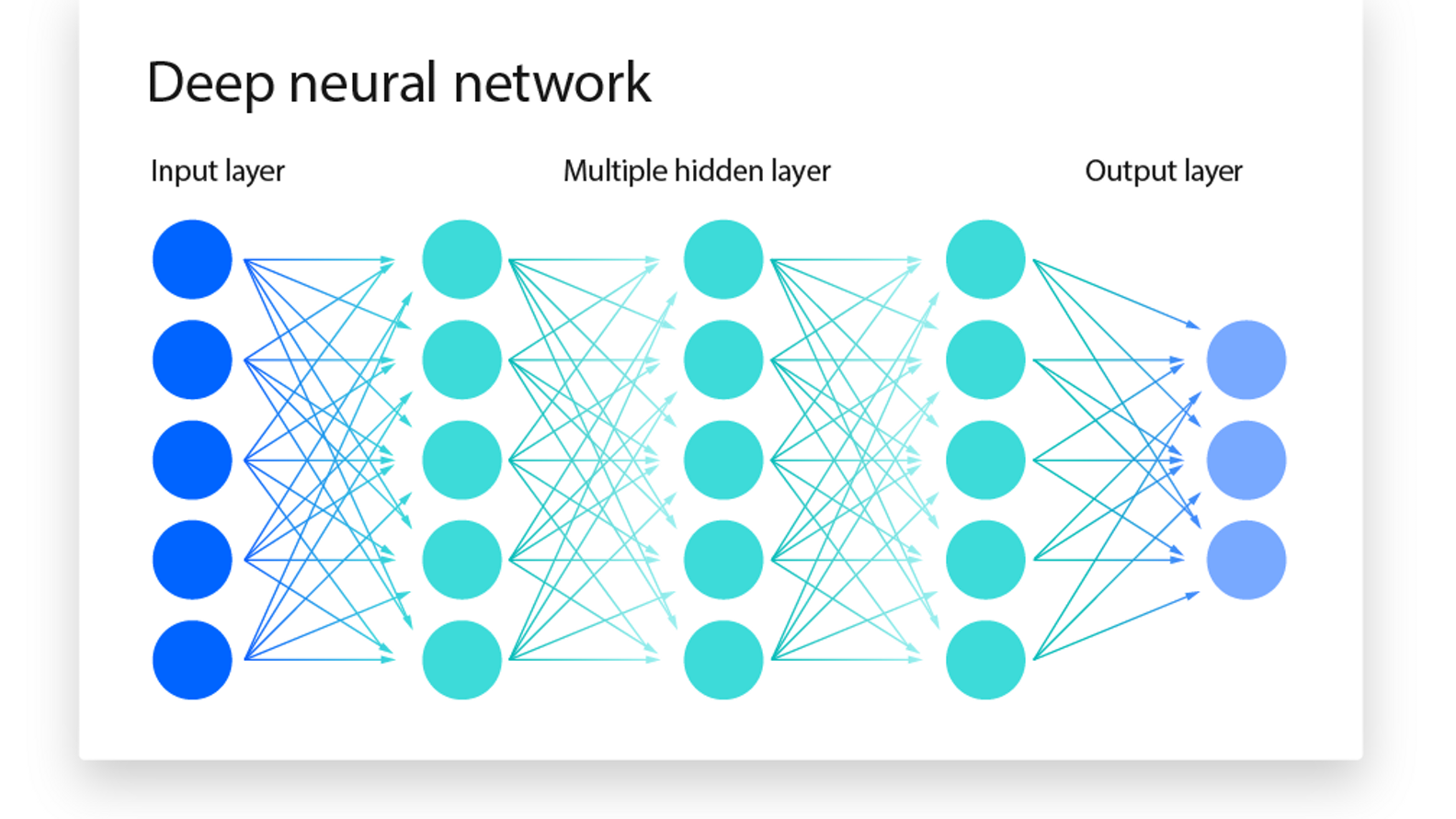
神经网络
神经网络是深度学习的基石!!
神经网络作为一种机器学习模型,通过将简易的"神经元"分层堆叠,从数据中学习模式识别的权重与偏置,从而建立输入到输出的映射关系。
神经网络是一种模拟人类大脑神经元网络的计算模型,它是深度学习的基础,属于机器学习的一个分支。神经网络由多个节点(或称为神经元)组成,这些节点通过权重相互连接,形成一个复杂的网络结构。
每个节点会对输入信号进行加权求和,并通过一个激活函数来决定是否将信号传递给下一层的节点。神经网络的学习过程涉及调整连接权重,以便网络能够准确地模拟或预测数据之间的复杂关系。
词嵌入与表示学习
要让神经网络理解语言,首先需要把"文字"变成"数字",词嵌入解决了这个问题。
词嵌入是自然语言处理(NLP) 中处理文本数据的「基石级核心技术」,所有复杂文本任务(情感分析、机器翻译、文本生成、问答系统)均基于词嵌入实现,是让计算机「真正看懂文本」的核心方法。
词嵌入(Word Embedding)是将人类语言中离散、抽象的文本词汇,通过算法映射为计算机可理解的「连续、稠密的低维实数向量」 的文本表示技术。本质是给每个词汇分配一个固定长度的数值数组(如 [0.23, 0.56, -0.12, ..., 0.71]),这个数组就是该词汇的「词向量」。
注意力机制与Transformer
没有注意力机制的旧模型里,信息要一步步传递,早期信息容易"遗忘",处理长句子时,开头的内容到后面就记不清了。有了注意力机制,任何位置的信息可以直连,不经过中间步骤,处理1000个词的长文,第1个词和第1000个词直接交流。
注意力 = 对所有信息进行加权求和,权重由"相关性"决定。
举个例子:翻译"我 爱 AI"
“我” ← 相关性 90%,权重 0.9
“爱” ← 相关性 8%, 权重 0.08
“AI” ← 相关性 2%, 权重 0.02
输出 = 0.9ד我” + 0.08ד爱” + 0.02דAI”
≈ “我”的信息(模型就知道该输出 I)Transformer 是一种完全基于注意力机制的神经网络架构。2017年Google提出,论文标题叫 《Attention Is All You Need》(你只需要注意力),意思是"只靠注意力机制就够了,不需要其他东西"。